
 ЖЖ Топ-50 постов сегодня
ЖЖ Топ-50 постов сегодня

Недавние тренды рунета
Последствия труднопредсказуемы, но одно очевидно, — грядет бум гаджетов-стимуляторов
Tранскраниальная стимуляция мозга в перспективе может заменить многие наркотики и ноотропы на пути обретения сверхчеловеческих когнитивных способностей. На рынке уже есть всевозможные гаджеты, обещающие улучшить настроение, снять страхи и депрессию, убрать боль, контролировать беспокойство и лечить бессонницу.
У всех этих гаджетов и лежащих в их основе методов есть два серьёзных ограничителя для их широкого распространения.
- Аналогичного эффекта можно достичь и без них с помощью традиционной и нетрадиционной медицины, разрешенных и не совсем наркотиков, все расширяющегося спектра ноотропов, а также алкоголя, медитации, секса … да мало ли чего еще.
- Все они обещают лишь убрать у человека какие-то неприятные ощущения или состояния (от депрессии до бессонницы), не даруя людям каких-либо важных и ценных для них новых качеств.
А вот если бы была возможность повысить свой интеллект!
Хочешь, например, изобретать или найти способ, как обойти конкурентов, или написать какую-то совершенно невообразимую ранее музыку, или …, — включил гаджет и вперёд.
Все современные «усилители интеллекта» — это всевозможные «таблетки для ума» (типа фенотропила) балансирующие на грани полной профанации и плацебо, т.к. никаких серьезных исследований, подтверждающих их эффективность, нет.
Что же до транскраниальных стимуляторов интеллекта, то их нет, поскольку никто не понимает, как можно повысить человеческий интеллект, толком не понимая, как он вообще работает.
И вот прорыв. Новое исследование «Right temporal alpha oscillations as a neural mechanism for inhibiting obvious associations» (правосторонние альфа-волны, как нейронный механизм подавления очевидных ассоциаций):
- во-первых, показало, как можно повысить интеллект, даже не понимая, как он работает;
- во-вторых, проверило действенность предложенного метода на 4х независимых экспериментах.
__ __ __ __ __
Первая из ключевых идей авторов нового исследования проста, но продуктивна,
— измерять креативность — важнейшую составляющую интеллекта.
В пользу такого подхода можно сказать следующее.
- Говорить о повышении интеллекта, есть смысл, только если понимаешь, как измерять его уровень.
- 30+ наиболее известных методов измерения уровня интеллекта выделяют один ключевой признак, по которому уровень интеллекта гениев всех времен и народов отсчитывается от тройки лидеров: №1 — Гёте, №2 — Ньютон и №3 — Эйнштейн.
Этот признак — продуктивная креативность человека — интегральный по времени показатель (т.е. накапливающийся с течением времени) значимости новых важнейших идей, привнесенных человеком в мир.
3) Тогда повышение креативности будет вполне обоснованно отражать повышение интеллекта.
Последнее из трёх замечаний в наше время становится все более актуальным. Креативность с каждым годом все более ценится абсолютно во всех сферах деятельности: от искусства, до науки и даже бизнеса.
Вторая ключевая идея нового исследования касается того, что стимулировать креативность можно,
просто настраивая наш мозг на выбор менее проторенных путей при размышлении и принятии решений.
“Выбор менее проторенного пути” считается эффективным подходом к творчеству (т. е. творческое мышление требует временного отказа от привычного мышления и ассоциаций). И хотя пока что мало известно о лежащем в основе этого нервном механизме, им вполне можно воспользоваться, если научиться настраивать мозг на более творческий подход.
И тут сработала третья ключевая идея нового исследования
— использовать альфа-волновое стимулирование мозга.
Известно, что альфа-колебания в мозге на частоте около 10 Гц характеризуют процесс активного ингибирования для подавления несущественной информации, такой, например, как ингибирование отвлекающих факторы при визуальном поиске.
Через контроль электрической активности мозга при выполнении различных творческих задач и путем стимулирования правой височной зоны мозга на альфа-частоте, авторы нового исследования показали, что подобный процесс активного торможения является также ключом к творческому мышлению.
Данные 4х экспериментов, проведенных в рамках исследования, указывают на то,
что правостороннее альфа-волновое стимулирование мозга может повышать творческие способности, задействовав нервный механизм для активного подавление очевидных семантических ассоциаций.
В результате
- мышление начинает идти по наименее проторенным путям;
- повышается творческий потенциал за счет новых неочевидных семантических ассоциаций;
- принимаются новые нестандартные решения.
Пока трудно сказать, какое будущее сулит человечеству это новое открытие. Поиск в сети термина «альфа-волновой стимулятор» (alpha wave stimulator) находит ссылки на грубые альфа-усиливающие устройства, работающие через прикрепленные к ушам электроды, которые, как утверждают, снимают боль, контролируют беспокойство, борются с депрессией или лечат бессонницу.
Новое исследование может в корне поменять ситуацию на рынке гаджетов для транскраниальной стимуляции мозга . По непроверенным данным, как минимум, уже три английских стартапа заинтересовались новым открытием за прошедшие две недели.
Если усилители креативности запустят в серию, нас ждет бум спроса на подобные гаджеты.
Гениальный Франсуа де Ларошфуко сказал,
«все жалуются на свою память, но никто не жалуется на свой ум».
Но это было сказано до изобретения «усилителя креативности». И теперь многие будут совсем не прочь стимулировать свой ум с помощью простого как смартфон гаджета.
Вот только за любое использование допинга надо потом платить… Но это уже другой вопрос.
________________________________
Если вам понравился этот пост — не забудьте:
- нажать “палец вверх”;
- подписаться на обновления канала на платформе Medium;
- оставить комментарий.
Еще больше материалов на моем Телеграм канале «Малоизвестное интересное». Подпишитесь
Оригинал и комментарии
1е открытие 2019 — возможности ИИ оказались небеспредельными
Подобно человеческому разуму, ИИ ограничен парадоксами теории множеств

До сих пор считалось, что самой фундаментальной проблемой развитии технологий ИИ является необъяснимость принимаемых им решений. В январе 2019 к этой проблеме добавилась еще одна, не менее фундаментальная проблема — принципиальная непредсказуемость, какие задачи ИИ может решить, а какие нет.
На пути триумфального развития технологий машинного обучения, как казалось, способных при наличии большого объема данных превзойти людей в чем угодно — в играх, распознавании, предсказаниях и т.д. — встала первая из 23 проблем, поставленных в докладе Давида Гильберта на международном математическом конгрессе в Париже еще в 1900-м году.
Первой в списке этих 23 проблем, решение которых до сих пор считается высшим достижением для математика, была так называемая гипотеза континуума (континуум-гипотеза или 1я проблема Гильберта), которую выдвинул и пытался решить (но потерпел неудачу) еще сам создатель теории множеств Георг Кантор.
И вот сейчас, на исходе второго десятилетия XXI века гипотеза континуума, будучи примененная к задачам машинного обучения, стала холодным отрезвляющим душем для всех технооптимистов ИИ.
Машинное обучение оказалось не всесильно
И что еще хуже, — в широком спектре сценариев обучаемость ИИ не может быть ни доказана, ни опровергнута.
__ __ __ __ __
Первая же научная сенсация 2019 года оказалась совершенно крышесрывательной. Опубликованная 7го января в Nature Machine Intelligence статья «Learnability can be undecidable» (Обучаемость может быть неразрешимой) устанавливает предел возможностей машинного обучения — ключевого метода вычислений, на коем стоит весь современный ИИ.
Этот научный вывод столь важен, что журнал Nature сопроводил статью еще двумя популярно её разъясняющими статьями «Unprovability comes to machine learning» (Недоказуемость приходит в машинное обучение) и «Machine learning leads mathematicians to unsolvable problem» (Машинное обучение приводит математиков к неразрешимой задаче).
Суть всех этих статей в следующем.
Обнаружены сценарии, в которых невозможно доказать, может ли алгоритм машинного обучения решить конкретную проблему.
Этот вывод может иметь огромное значение, как для существующих, так и для будущих алгоритмов обучения.
Обучаемость ИИ не может быть ни доказана, ни опровергнута с использованием стандартных аксиом математики, поскольку это связано с парадоксами, открытыми австрийским математиком Куртом Гёделем в 1930-х годах.

Парадоксы бесконечности
Теория множеств, так или иначе, является основой большинства разделов математики.
Парадоксы — это формально-логические противоречия, которые возникают в теории множеств и формальной логике при сохранении логической правильности рассуждения. Парадоксы возникают тогда, когда два взаимоисключающих (противоречащих) суждения оказываются в равной мере доказуемыми.
С точки зрения математики, вопрос «обучаемости» сводится к тому, сможет ли алгоритм извлечь шаблон из ограниченных данных. Ответ на этот вопрос связан с парадоксом, известным как вышеупомянутая континуум-гипотеза (проблема континуума или 1я проблема Гильберта) и разрешенным в 1963 г. американским математиком Полом Коэном.
“Решение оказалось весьма неожиданным: то, что утверждается в гипотезе континуума, нельзя ни доказать, ни опровергнуть,
исходя из аксиом теории множеств. Гипотеза континуума логически независима от этих аксиом. Неспециалисту довольно трудно понять, почему утверждения такого рода играют для математики столь большую роль и ставятся на первое место в списке важнейших проблем. Отметим лишь, что на самом деле речь идет о вещах принципиальных и фундаментальных,
так как континуум — это, по сути, базовая математическая модель окружающей нас физической, пространственно-временной реальности (частью которой являемся и мы сами),
а в математике континуум — еще и синоним совокупности всех действительных чисел, также центрального понятия математики и ее рабочего инструмента”.
(подробней см. в Кратком конспекте лекций для аспирантов-математиков «Философские проблемы математики» С. Н. Тронина).
По сути Гёдель и Коэн доказали, что континуум-гипотеза не может быть доказана ни как истинная, ни как ложная, начиная со стандартных аксиом — утверждений, принятых как истинные для теории множеств, которые обычно принимаются за основу всей математики.

Иными словами, — утверждение не может быть ни истинным, ни ложным в рамках стандартного математического языка.
Что не менее важно, работа Гёделя и Коэна над континуум-гипотезой подразумевает, что
могут существовать параллельные математические вселенные, которые совместимы со стандартной математикой — одна, в которой гипотеза континуума добавляется к стандартным аксиомам и поэтому объявляется истинной, а другая — в которой она объявляется ложной.
Не все наборы данных равны
Исследователи часто определяют обучаемость с точки зрения того, может ли алгоритм обобщать свои знания. Алгоритм сначала учится давать ответ на вопрос «да или нет» (например «показывает ли изображение кошку?») для ограниченного числа объектов, а затем алгоритм должен угадывать ответы для новых объектов.
Авторы нового исследования пришли к своему результату, исследуя связь между обучаемостью и «сжатием», подразумевающим поиск способа суммировать характерные особенности большого набора данных в меньшем наборе данных. Авторы обнаружили, что способность информации эффективно сжиматься сводится к вопросу из теории множеств. В частности, это относится к разным размерам множеств, содержащих бесконечно много объектов.
Т.о. с точки зрения математики,
обучаемость — это способность делать прогнозы для большого набора данных путем выборки небольшого числа точек данных.
Однако существует бесконечно много способов выбора меньшего множества, и размер этой «бесконечности» неизвестен.
- Если континуум-гипотеза верна, то для экстраполяции достаточно небольшой выборки.
- Но если это неверно, никакой конечной выборки может быть недостаточно.
В итоге получается, что проблема обучаемости эквивалентна континуум-гипотезе.
Следовательно, проблема обучаемости также находится в состоянии неопределенности, которая может быть решена только путем выбора аксиоматической вселенной.
Как отмечают авторы, — “недоказуемость приходит в машинное обучение”.
«В 2019 году машинное обучение превратилось в математическую дисциплину, объединяющую многие области математики, которые связаны с бременем недоказуемости и сопутствующими ему заморочками. Возможно, результаты, подобные этому, привнесут в область машинного обучения здоровую дозу смирения, даже если алгоритмы машинного обучения продолжат революционизировать мир вокруг нас».
__ __ __ __ __
Вот и получается, что знаменитая фраза В.Ерофеева справедлива и для машинного обучения, — в нашей математической вселенной
«все должно происходить медленно и неправильно, чтобы не сумел загордиться человек, чтобы человек был грустен и растерян».

Ну а кого это не устраивает, могут попробовать сменить нашу математическую вселенную на какую-то иную.
________________________________
Если вам понравился этот пост — не забудьте:
- нажать “палец вверх”;
- подписаться на обновления канала на платформе Medium;
- оставить комментарий.
Еще больше материалов на моем Телеграм канале «Малоизвестное интересное». Подпишитесь
Оригинал и комментарии

Известная по своей вводящей в заблуждение и лженаучной рекламе российская компания “Генотек” (опять) опубликовала очередное исследование.
В принципе, ничего нового. Но достаточно показательно для понимания того, как работает коммерческая наука вообще и компания “Генотек” в частности.
Речь в этот раз идет о “генах алкоголизма”. Именно их у россиян обнаружили специалисты этой компании.

Сравнив наборы нескольких тысяч мелких мутаций в ДНК всех четырех групп добровольцев, генетики выделили несколько генов, связанных со склонностью к алкоголизму, часть из которых ученые раньше не открывали в геномах жителей других стран.
Оставим научно-популярное изложение, свойственное российской прессе, у нее же на совести. И обратимся к оригинальной (неопубликованной пока нигде) статье “Генотека”, которую они услужливо выложили в bioRxiv.
Что мы там видим интересного?
Авторы
Целая коллегия авторов из разных организаций. Все, кажется, очень серьезно.
- Genotek Ltd.
- Pirogov Russian National Research Medical University, Ostrovityanova str 1, 117997, Moscow, Russia
- Institute of Biomedical Chemistry, Pogodinskaya street 10 build. 8, 119121, Moscow, Russia
- Vavilov Institute of General Genetics, Gubkina str 3, 119333, Moscow, Russia
- Lomonosov Moscow State University, Faculty of Mechanics and Mathematics, Leninskiye Gory, Main building, 119991, Moscow, Russia
Методология
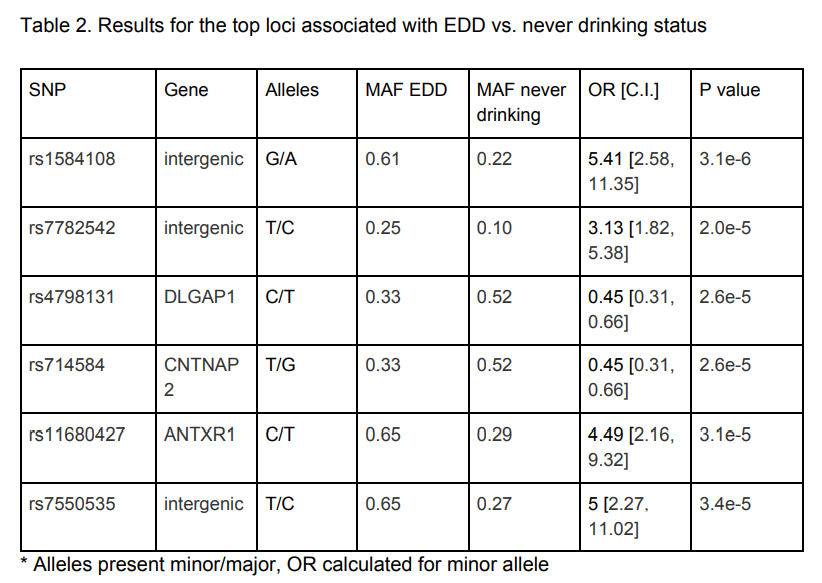
В общей сумме авторами проанализированы геномы 1008 человек на чипе с 500 000+ SNP. Hайдено 5 кандидатов на связь с алкоголизмом.
Например (обратите внимание на p-values в таблице, мы к ним еще вернемся) в таблице:
Научная ценность
Собственно, все уже догадались и она напрямую следует из методологии. Но я попробую коротко объяснить.
Даже если отбросить мою категорическую нелюбовь к методам Фишера, работа представляет собой полный буллшит. Ключевая проблема носит название проблемы “множественных сравнений”, об этом много где писано, но я попробую объяснить еще раз.
Каждый раз, когда в ограниченном числе шумных данных вы ищете бесконечное число корреляций — вы их находите. Теория вероятностей не только разрешает найти подобные случайные корреляции, но гарантирует их находку. Просто потому что теория вероятностей — это не про равномерность и постоянство нашего мир. Она про случайности и совпадения. И она предсказывает, что чем вы тщательнее ковыряетесь в данных — тем больше будет подобных совпадений. Потому что они там есть. Но они совпадения, а не закономерности. То есть, конечно, закономерности тоже могут быть, но отделить одно от другого непросто и именно для этого и применяются статистические методы.
В случае с полногеномными поисками ассоциаций (Генотек — работа является представителем именно такого типа поиска) такая проблема, часто ее называют проблемой множественных сравнений, стоит особенно остро. Одновременно тестируется огромное количество гипотез (равное количеству SNP, в нашем случае полмиллиона).
Разумеется, в общем случае исследователи это понимают, и не используют общепринятый уровень значимости 0.05.
Условным стандартом для подобного рода исследований давно стала альфа = порядка 1e-8 — 5e-8*.
Возьмем крайнее значение и оттолкнемся от него.
Иными словами. Если p < 5е-8, то найденная ассоциация статистически значима и, возможно, не случайна. Если > 5е-8, то мы не смотрим в эту сторону. В этом случае ассоциация считается шумом и случайностью и размышлять о взаимосвязях рановато.
Теперь еще раз посмотрим в таблицу из работы российских авторов и особенно пристально в последний столбец и сделаем выводы.
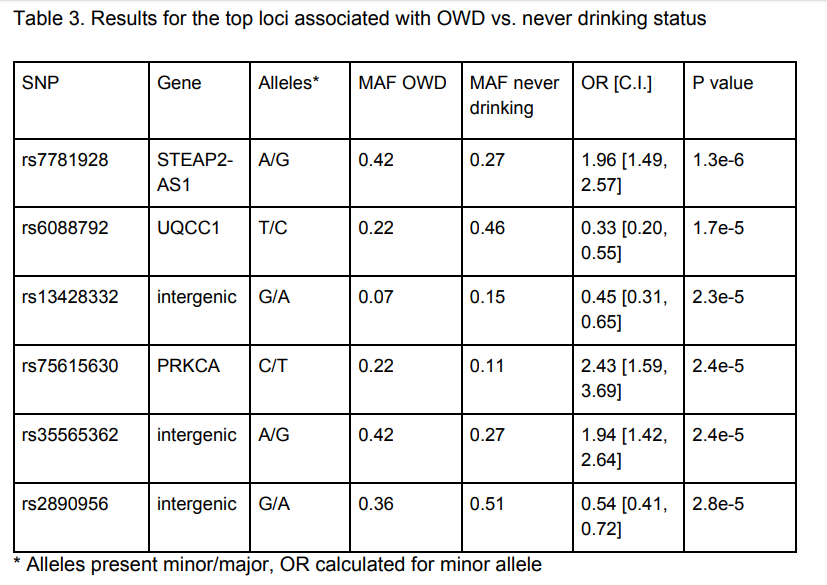
Как можно заметить невооруженным глазом, ни одна из ассоциаций даже близко не приближается к статистической значимости. Лучшее, что удалось достичь — это 1е-6 при желаемых хотя бы 5е-8.
То есть примерно в 20 раз больше. Авторы даже близко не подошли к тем цифрам, при которых можно только начать говорить о возможной взаимосвязи. И совершенно неважно, что в выводах к своей работе авторы пишут, что нашли несколько генов, которые связаны с потреблением алкоголя:
This study presents the GWAS of alcohol consumption in Russian population and identifies several genetic loci in genes involved in nervous system function and mental disorders with some alcohol drinking patterns. Further independent studies are required to confirm these findings.
Единственный вывод, который напрямую следует из данных, должен быть сформулирован по-другому:
В результате проведенной работы нам не удалось выявить ни единого участка ДНК, который мог бы быть ассоциирован с алкоголизмом у россиян.
Это,конечно, не значит, что подобных генов нет вообще. Может и есть, просто статистическая мощность данного исследования (всего 1008 человек) не позволила их выявить.
Следует добавить, что, как уже сказано выше, статья пока нигде не опубликована. И, я надеюсь, никогда не будет. Потому что к науке это не имеет никакого отношения.

Даже к российской.
_____________________________
* Порог, который используется для определения статистической значимости в GWAS — тема очень горячая и дискуссионная. В некоторых источниках рекомендуется использовать 5e-8, в других до 1e-8, в третьих рассчитывать индивидуально под каждое конкретное исследование, что кажется наиболее верным, но все равно никак не выше, чем 5e-8.
Важно то, что это вроде бы достаточно низкая величина на самом деле не низкая. Она возникает в результате поправки порога статистической значимости для тестирования одной гипотезы на множественные сравнения, связанные с одновременным определением многих сотен тысяч SNP.
Оригинал и комментарии

По наводке читателя, с интересом познакомился с превосходной медиапродукцией современного последователя Джеффа Питерса и Энди Таккера по имени Кли Ирвин.
Если Джефф и Энди 100 лет назад зарабатывали на жизнь с помощью довольно простого, но весьма творческого мошенничества (эксплуатируя человеческие жадность, глупость, страх и тщеславие), то Кли сегодня собирает на порядки больше, доведя мошенничество до такого уровня, что его предшественникам даже и не снился.
Вот классный ролик от Кли Ирвина — «Теория Симуляции — Взлом Реальности», сделанный на уровне Спилберга, если бы тот вдруг решил работать на National Geographic или на BBC Science.
Превосходно всё — от сценария до анимации, от монтажа до звука и т.д. (насладитесь 🤪)
Но больше всего поражает уровень популярной завлекательности в подаче и донесении «майн кампфа» Кли Ирвина — «Emergence Theory».
Это «теория точечного пространства-времени и реальности, как квазикристаллического точечного пространства, спроецированного из кристалла E8». Цель теории — создание единой и непротиворечивой концептуальной модели мира, объединяющей теорию относительности и квантовую механику с феноменами информации и сознания.
К чему я веду?
А к тому, чтобы проиллюстрировать, до какого запредельного уровня привлекательности и убедительности для людей, не обладающих всей полнотой информации по какой-либо теме, может доходить фейковая медиареальность в руках талантливых и экстра-креативных мошенников.
Но это еще не самое страшное, а вот что.
Новое исследование «People use less information than they think to make up their minds» подводит нас к довольно поразительному и неожиданному выводу.
- Доступ ко всей полноте информации, способный, казалось бы, кардинально влиять на человека в наш информационный век, мало кого спасает.
- Для подавляющего большинства доступ к обильной информации НЕ способствует формированию у них более информированных мнений и суждений.
- В итоге, чем к большему объему информации люди имеют потенциальный доступ, тем менее объективно информированным становится большинство.
Результат очевиден:
Информационное общество XXI века обречено на расцвет фейковых новостей и псевдонаучных заманиловок, типа «Emergence Theory», проекта «Чистая вода» и много-много чего еще.
________________________________
Если вам понравился этот пост — не забудьте:
- нажать “палец вверх”;
- подписаться на обновления канала на платформе Medium;
- оставить комментарий.
Еще больше материалов на моем Телеграм канале «Малоизвестное интересное». Подпишитесь
Оригинал и комментарии
Страшная сила великой безответственности

Прочтя за праздники больше сотни разнообразных материалов с анализом итогов 2018 и прогнозами на 2019 в области ИИ, я попытался как-то отжать из них общий сухой остаток для своих читателей.
Заголовок поста — это то, что получилось.
• 1е предложение — взгляд оптимистов
• 2е — пессимистов.
Для иллюстрации взглядов оптимистов я использую итоговый отчет по ИИ за 2018 издания The Verge.
В роли пессимистов, как и положено по названию, — у меня выступит редакция The Guardian со своим прогнозом ИИ «Мир в 2019».
The Verge
2018 ознаменовался парадом негативных заголовков о скандальных результатах и перспективах ИИ проектов.
- первые смертельные жертвы самоуправляемых авто;
- фирма Кембридж Аналитикс оскандалилась в попытках влияния на общественное мнение;
- компанию Facebook обвинили, что она способствовала геноциду в Мьянме;
- а компанию Google — в том, что помогала Пентагону обучать военные беспилотники;
- все технологические ассоциации, не сговариваясь, бьют в набат об огромном риске непроработанности этических вопросов ИИ.
Эти и многие другие примеры сподвигли исследовательскую группу AI Now охарактеризовать 2018, как год «каскадных скандалов» в области ИИ. И это точное, хотя и удручающее, определение.
В то же время, The Verge считает, что лучше уж публичные скандалы, чем заметание сора под ковёр. И если открыто клеймить все скандалы и обличать жадность и дурь тех, кто пытается использовать ИИ для своих низких целей или просто из-за суетливого желания застолбить за собой поляну с помощью недостаточно проработанных решений с непродуманными последствиями, — есть шанс, что всё понемногу образуется.
А другими словами, — ИИ может и сгубит мир, но не сразу, а мы еще успеем как следует помучиться. Вот такой оптимизм получился.
Теперь про анализ The Guardian
1) 2018 показал, что уровень ИИ технологий и человеческой глупости растут неимоверно быстро. И в 2019 нужно более всего опасаться слияния этих двух трендов.
2) Правительства, похоже, для себя вопрос с ИИ решили. Прагматический Китай не стесняясь заявил, что будет максимально использовать ИИ для «прогнозирования траекторий развития интернет-инцидентов … превентивного вмешательства и управления общественным мнением для предотвращения массовых вспышек общественного мнения в Интернете и улучшения возможностей социального управления». Скромные правительства Запада вслух такого пока не говорят, но с интересом смотрят, что у Китая получится, чтобы сделать работу над ошибками.
3) В 2018 произошел концептуальный прорыв Google DeepMind в создании AlphaZero — самообучаемого класса программ, способных без участия человека в течение всего нескольких дней достигать сверхчеловеческого уровня в любой игре с «идеальной информацией», где все факты игры известны всем игрокам. Этот прорыв ставит крест на попытках сменить курс разработки ИИ систем в сторону понимаемого человеком способа решения задач ИИ программами. AlphaZero подход делает окончательно невозможным реконструировать процесс, по которому программы приходят к своим выводам, как решать задачу.
Вот превосходный рассказ всей истории AlphaZero
4) Второе великое событие прошлого года немерено повышает риски от использования ИИ. В 2018 рост мощности HW и SW, сопровождаемый повсеместным триумфом облачных технологий, привел к полной демократизации ИИ технологии (они теперь доступны практически всем), но на самом деле это полная анархизация использования ИИ. Теперь все, от авторитарных правителей до криминала, получают в руки мощнейшие инструменты, и то, как они их применят, зависит лишь от уровня креативности их консультантов.
Вот свежий превосходный пример демократизации ИИ
________________________________
Если вам понравился этот пост — не забудьте:
- нажать “палец вверх”;
- подписаться на обновления канала на платформе Medium;
- оставить комментарий.
Еще больше материалов на моем Телеграм канале «Малоизвестное интересное». Подпишитесь
Оригинал и комментарии
Два новых открытия позволяют увидеть мир иначе, чем представлялось

✔️ Мы привыкли думать, что в основе затейливой сложности мира какие-то замысловатые процессы и мудреные законы.
✔️ Всё новые открытия свидетельствуют об обратном: мир устроен на основе чрезвычайно простых паттернов, организованных по совсем простым принципам.
Выявить эти закономерности можно из практически любых массивов данных, анализировать которые раньше просто не приходило в голову.
Каким образом это теперь приходит в головы исследователей, остается загадкой, про которую можно лишь сказать эпиграфом из Гоголя к повести Стругацких «Понедельник начинается в субботу».
«Но что страннее, что непонятнее всего, это то, как авторы могут брать подобные сюжеты, признаюсь, это уж совсем непостижимо, это точно… нет, нет, совсем не понимаю. Н.В. Гоголь»
Вот эти два открытия.
1) Биологические закономерности, определяющие формирование рисунка перьев у цыплят, развитие волос млекопитающих, структуру зубообразных выступов на коже акул и др., — описываются простыми паттернами математической модели, придуманной Аланом Тьюрингом, придумавшим «мать всех компьютеров» — машину Тьюринга и приблизившего окончание Второй мировой войны, взломав немецкий секретный код Enigma (см. прекрасный фильм «Игра в имитацию»).
Модель Тьюринга, называемая модель реакции-диффузии, очень проста. Для неё требуются только два взаимодействующих вещества, активатор и ингибитор, которые диффундируют через ткань, подобно чернилам, уроненным в воду. Активатор инициирует некоторый процесс, такой как формирование пятна, и способствует воспроизводству самого себя. Ингибитор останавливает этот процесс. Важно отметить, что ингибитор распространяется через ткани быстрее, чем активатор. Это более быстрое распространение ингибитора предотвращает переполнение очагов активации. В зависимости от того, когда и где высвобождаются активатор и ингибитор, области активации будут располагаться в виде равномерно расположенных точек, полос или других рисунков. В результате получаются регулярные паттерны роста перьев, чешую или даже зубов.
Подробней:
- научная статья
- также рекомендую 4х минутный ролик про Реакцию диффузии — завораживающее зрелище под гипнотизирующую музыку.
2) Пунктуация любого литературного текста описывается простыми паттернами, по которым, как по отпечаткам пальцев, можно определить автора текста и его жанр.
- То, что по результатам анализа текста можно определить его автора, сегодня мало кого удивишь.
- То, что можно выкинуть все слова, оставив лишь знаки препинания, и по их последовательности и частоте можно также определить автора, звучит бредово, но это факт.
Вот на картинке показаны хитмапы анализа пунктуации трех разных авторов, по которым их можно вычислить, не прочтя ни одного слова в их текстах — только по пунктуации.
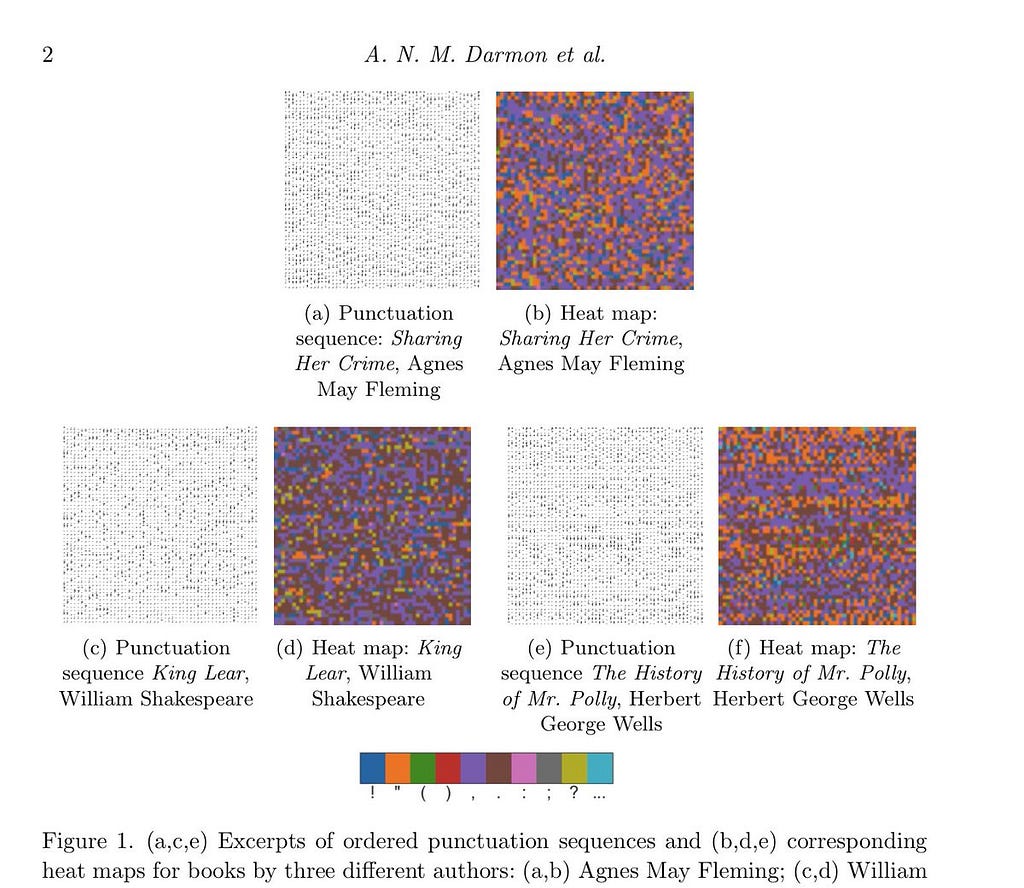
Подробней:
• популярная статья еще только пишется
________________________________
Если вам понравился этот пост — не забудьте:
- нажать “палец вверх”;
- подписаться на обновления канала на платформе Medium;
- оставить комментарий.
Еще больше материалов на моем Телеграм канале «Малоизвестное интересное». Подпишитесь
Оригинал и комментарии
Новое исследование измерило интеллектуальную фору, даваемую чтением маленьким детям

Bсе знают — малышам нужно читать. Но в жизни много чего «нужно». А время у родителей не резиновое. И есть приоритеты поважнее чтения малышам. Посему, спел песенку на ночь и пошел. А читать ему времени нет, — пусть растет и сам читает.
Оказалось, что цена, которую придется заплатить ребенку за такой подход родителей, весьма высока.
Примерно восьмимесячное отставание от тех, кому много читали.
А ведь 8 месяцев — это большая разница в языковых навыках, когда речь о детях в возрасте до 5 лет.
Причем:
1) речь идет об отставании буквально во всех языковых навыках:
- восприятие языка (понимание);
- экспрессия языка (как ребенок складывает свои мысли в слова, используя словарный запас и грамматику);
- навыки пред-чтения (например, структурирование слов).
2) отставание в языковых навыках (языковых аспектах интеллекта) предсказывает последующие социальные и образовательные трудности, которые, как показывают исследования, потом труднее всего изменить.
Резюме.
Читайте малышам как можно больше. Для их будущей жизни это важнее, чем унаследованный миллион баксов, который вы наивно хотели бы заработать, сэкономив время на чтении своим малышам.
Подробней: популярно + отчет исследования + материалы исследования
Общее руководство по развитию языковых навыков + спецотчет.
А это совсем коротко — языком плаката.
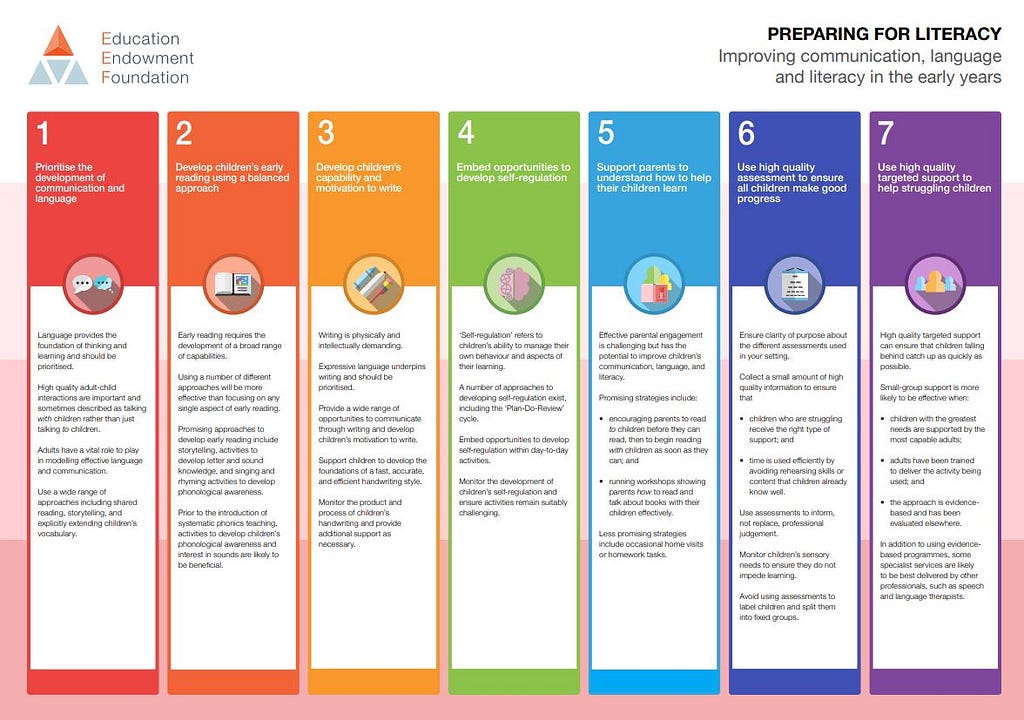
P.S. И даже если вам в детстве мало читали, не повторяйте этой ошибки сейчас, когда речь идет о ваших детях и внуках.
________________________________
Если вам понравился этот пост — не забудьте:
- нажать “палец вверх”;
- подписаться на обновления канала на платформе Medium;
- оставить комментарий.
Еще больше материалов на моем Телеграм канале «Малоизвестное интересное». Подпишитесь
Оригинал и комментарии
Это более вероятно, чем вы думаете

Пишу об этом уже 2 года. Последний раз всего 12 дней назад — 8го января (ссылка в конце).
Спрашивается, — сколько можно стращать, и зачем так чащу?
Да затем, что еще со времен Кассандры известно, что умное планирование подразумевает обязательный учет наихудшего сценария. И не делать это чревато …
Отклики читателей на мой пост от 8 января были разнообразны.
Оппоненты приводят, в основном, две группы контраргументов.
- Будущее принципиально непредсказуемо, и потому все прогнозы мало чего стоят.
- Статистические выкладки не заслуживают доверия, потому что (1) неполные данные и/или потому, что (2) тренды кардинально изменились — формальных доказательств этого нет, но статистика последних десятилетий обнадеживает (читайте Стивена Пинкера).
Что на это ответить? … Не знаю.
Но вот Уго Барди — автор работы, о которой я писал 8го января (профессор физической химии универа Флоренции, уже 10+ лет специализирующийся на матанализе экзистенциальных прогнозов) позавчера в своем блоге ответил оппонентам так.
«Недавно вместе со своими коллегами я занимался статистическим анализом войн за последние 600 лет. Результаты были отрезвляющими: война, похоже, является статистическим явлением, подобным землетрясениям и лесным пожарам.
Войны возникают в соответствии с четко определенными статистическими закономерностями, и с этим мало что можно поделать.
Аарон Клуазет — другой ученый, который работает над той же самой темой, в весьма отрезвляющем анализе рассчитал вероятности будущих войн.
По его подсчетам, крупная война масштаба 2й мировой имеет более 40% шансов произойти в течение ближайших 100 лет.
А война с более чем миллиардом погибших, которая может уничтожить большую часть человечества, с вероятностью 5% может произойти менее чем за 4 столетия.
Самое важное здесь то, что сказанное вовсе не значит, что мы можем расслабиться на ближайшие 4 века. Совсем нет.
Математически правильная трактовка этого прогноза — мы можем ожидать уничтожения значительной части человечества с 5%ной вероятностью в ЛЮБОЙ МОМЕНТ будущего, в течение ближайших 4 столетий».
Осталось осознать, что же представляет собой 5%ная вероятность.
Представьте такой вариант при игре в кости. Например, выпадает шестерка, а затем еще раз шестерка или пятерка. Вероятность того, что этот вариант может случиться при ваших 2х очередных бросках и есть примерно 5%.
Поставите судьбу человечества на кон, утверждая, что такой вариант крайне маловероятен?
__ __ __

Блог Уго Барди называется «Завет Кассандры — всегда планируйте возможность наихудшего сценария».
И это не алармизм, а житейская мудрость, которую люди всегда знали и никогда ей не следовали.
Как у В.С.Высоцкого:
Без умолку безумная девица
Кричала: “Ясно вижу Трою павшей в прах!”
Но ясновидцев — впрочем, как и очевидцев -
Во все века сжигали люди на кострах.
Допматериалы:
- Пост Уго Барди
- Мой пост «Окончательный диагноз — большой войны не миновать»
________________________________
Если вам понравился этот пост — не забудьте:
- нажать “палец вверх”;
- подписаться на обновления канала на платформе Medium;
- оставить комментарий.
Еще больше материалов на моем Телеграм канале «Малоизвестное интересное». Подпишитесь
Оригинал и комментарии
Оригинал и комментарии

Этот сценарий сегодня видится весьма вероятным профессору Дереку Боундсу — одному из самых уважаемых мною интеллектуалов.
1) Западные правительства — импотенты.
Запад душит свою экономику, дестабилизирует политику и разрушает демократию. Правительства США, Великобритании и не только — бесполезны и едва ли способны управлять собой, не говоря уже о формировании мирового порядка. В отсутствие у правительств разума и воли, общество дрейфует к моменту цивилизационного самоотрицания. А в это время, не брезгующий самыми безжалостными средствами и обладающий огромными ресурсами Си Цзиньпин поднял знамя эффективного авторитаризма, как предпочтительной модели управления 21-го века.
Подробней по 1й ссылке в посте Дерека.
2) Вся надежда на мегакорпорации.
Это они, доминирующие в потоках капитала США и всего мира, становятся куда более устойчивым буфером против хаоса, чем любое отдельное правительство. И теперь их долг — выйти за целевые рамки получения прибыли и внести свой решающий вклад в развитие общества, служа социальным целям. С таким призывом к мегакорпорациям обратился сам Ларри Финк — глава крупнейшей в мире инвестиционной компании BlackRock.
Подробней по 2й ссылке в посте Дерека.
3) Но тогда вопрос — а на кого работают мегакорпорации?
И ответ на него крайне малоутешителен — на новую аристократию, составляющую сегодня 10% любого современного общества. У них не просто много денег. У них значительно ниже показатели сердечно-сосудистых заболеваний, диабета и ожирения. Они позже заключают браки, которые оказываются более стабильными. Они живут в богатых кварталах, имеют превосходный круг друзей и отличные образовательные возможности. И главное, — они могут все это передать детям, оставляя 90% остальных тщетно колупаться в пыли на дне общества.
Но ведь история показывает, что растущее неравенство имеет свои фазовые переходы. Превзойдя некую границу, оно порождает катастрофическое насилие (хотя бывали, хоть и редкие, но исключения).
Подробней по 3й ссылке в посте Дерека.
А если коротко за 3 мин, то вот видео, которое стоит посмотреть, даже если вы не будете дальше ничего читать по этой теме.
А это пост Дерека Боундса
________________________________
Если вам понравился этот пост — не забудьте:
- нажать “палец вверх”;
- подписаться на обновления канала на платформе Medium;
- оставить комментарий.
Еще больше материалов на моем Телеграм канале «Малоизвестное интересное». Подпишитесь
Оригинал и комментарии
Ненависть — это хорошая штука. Просто с ней надо уметь работать.
Люди довольно часто занимаются самокопанием и прочими самопознавательными практиками. Тесты там всякие сдают, пытаются понять, к чему они пригодны. Отвечают на вопрос: «Кто я?» снова, и снова, и снова, и снова.
ТЫ ТОЧНО НЕ ТОТ, КОГО НЕНАВИДИШЬ.
Если составить список мерзких поступков и качеств, за которые ненавидел бы даже себя любимого, то возникает довольно четкая граница, внутри которой живет твоя суть.
Нет! Это не те поступки, которые ты втайне хочешь совершить, но никогда никому в этом не признаешься. Это те, за которые раскаивался бы до конца дней своих даже на необитаемом острове, где некому исповедоваться.
От настоящей ненависти до любви пропасть. Это не то, что может вдруг свичнуться в иное состояние. Как гигантская сороконожка, заползающая к тебе под одеяло, предмет ненависти вызывает резкое и однозначное чувство неприемлемого.
Неприемлемое неприемлемо. Все остальное – возможности. Всем остальным, в теории, ты можешь быть, если захочешь.
Оригинал и комментарии
Конечно, не сейчас, когда вокруг ИИ так много шумихи и денег, но со временем

Некоторые из моих читателей (даже весьма продвинутых в ИИ) убеждены, что проблема черного ящика ИИ — это вчерашний день. Мол, задача объяснимости решений, принимаемых ИИ, говоря по Маяковскому, — «будет сделана и делается уже».
А ведь это совсем не так.
Проект DAPRA Explainable Artificial Intelligence (XAI) — Объяснимый ИИ (о котором я пишу в своем канале с 2016) — пока буксует. Только что закончившаяся 1я фаза проекта не принесла желаемого результата. 2я фаза продлится до мая 2021. Но как говорят участники проекта, хороших идей пока нет.
Компания Google (которая в вопросах ИИ точно не слабее DARPA), подобно Ленину, пошла другим путем. И путь этот окольный:
- вместо общего решения задачи построения объяснимого ИИ, способного в принципе устранить проблему черного ящика,
- Google решил построить инструментарий, позволяющий хотя бы исследовать, на какие факторы ИИ обращает внимание при решении задачи, а на какие нет, и насколько высокие веса при решении задачи ИИ присваивает тем или иным факторам.
Как и всякий окольный путь, подход Google — долгий и без гарантий не опоздать. Но зато можно было бы долго вешать лапшу на уши рынку.
Вот почему так поразительно откровенно смелое интервью Бин Ким (Been Kim), целенаправленно исследующей в Google Brain вопрос интерпретируемости ИИ.
Вот ответы Бин Ким на 2 ключевых вопроса.
- Насколько важно сейчас решение проблемы интерпретируемости ИИ?
БК: «Сейчас для ИИ настал критический момент: человечество пытается решить, хороша эта технология для нас или нет. Если мы не решим проблему интерпретируемости, вряд ли мы возьмём эту технологию с собой в будущее. Может быть, человечество просто забудет про неё». - Если в принципе может случиться отказ от ставки на машинное обучение, как технологической базы ИИ разработок, когда это могло бы произойти?
БК: «Не думаю, что это произойдёт прямо сейчас, когда вокруг ИИ много шумихи и денег. Но я думаю, что в долгосрочной перспективе человечество может решить — возможно, из-за страха, возможно, из-за отсутствия доказательств [безопасности] — что эта технология не для нас. Может так случиться».
Это честное и смелое интервью Бин Ким уже перевели и на русский.
А это видео интервью.
В заключение отмечу.
Google — весьма серьезная мегокорпорация. И просто так её ведущие сотрудники в прессе не болтают. Тем более, о стратегических для компании вопросах.
Тогда что же стоит за столь откровенным интервью Бин Ким?
Возможно, это значит, что Google уже работает над альтернативным направлением и начала готовить для него почву в медиа.
Так что есть над чем задуматься убежденным технооптимистам, считающим, что задача устранения черного ящика ИИ «будет сделана и делается уже».
________________________________
Если вам понравился этот пост — не забудьте:
- нажать “палец вверх”;
- подписаться на обновления канала на платформе Medium;
- оставить комментарий.
Еще больше материалов на моем Телеграм канале «Малоизвестное интересное». Подпишитесь
Оригинал и комментарии
Используйте его сами и учите по нему детей, а еще примите участие в эксперименте

Про это метод, полагаю, никто из вас даже не слышал. А ведь штука весьма полезная.
Суть идеи проста и очевидна — чтобы людям лучше понимать и запоминать ценную информацию, нужно у них предварительно задействовать элемент личной заинтересованности.
Для этого и придуман метод опережающей интерактивной визуализации:
- сначала спросить, заинтриговав «загадкой»;
- потом визуализировать «загадку» в максимально простой и понятной форме (в идеале, инфографикой);
- потом мотивировать человека думать, что и даст нужный результат: улучшение понимания и запоминания до 300%.
✔️ Чтобы все это прочувствовать на практике, поучаствуйте в эксперименте. Он очень интересен, информативен, полезен и, точно, вас удивит.
- Пройдите по ссылке.
- Вам покажут 10 статистических данных о мире, а затем попросят пройти быстрый анонимный опрос.
- В конце января будут представлены результаты, о которых вы узнаете в блоге автора эксперимента — великолепного Ники Кейса .
➡️ Не читающим по-английски — ниже перевод вопросов (так вы легко пройдете эксперимент)
Вопрос 1: Какой % населения мира живет при демократии?
Вопрос 2: какой % населения мира имеет хотя бы одно психическое расстройство или расстройство, связанное со злоупотреблением психоактивными веществами?
Вопрос 3: как изменился со временем уровень смертности от самоубийств в мире?
Вопрос 4: как рождаемость в мире (среднее число детей на маму) изменились с течением времени?
Вопрос 5: Каков % смертности в мире от сердечно-сосудистых заболеваний?
Вопрос 6: какой % смертей во всем мире приходится на хомицид — т.е. убийства + война + терроризм вместе взятые?
Вопрос 7: как изменилось со временем количество ядерных боеголовок в мире?
Вопрос 8: как изменилось со временем мировое соотношение людей, живущих в условиях крайней нищеты?
Вопрос 9: как изменилось загрязнение воздуха с течением времени?
Вопрос 10: насколько изменились глобальные годовые выбросы CO2 с течением времени?
ℹ️ Этот эксперимент был вдохновлен проектом New York Times «You Draw It» на тему «Как скачок передозировки наркотиков соотносится с другими причинами смертности в США?»
Весьма рекомендую посмотреть и его — познавательная и интересная иллюстрация метода опережающей интерактивной визуализации
Про память я пишу посты регулярно — см. в Телеграм-канале по тэгу #Память
________________________________
Если вам понравился этот пост — не забудьте:
- нажать “палец вверх”;
- подписаться на обновления канала на платформе Medium;
- оставить комментарий.
Еще больше материалов на моем Телеграм канале «Малоизвестное интересное». Подпишитесь
Оригинал и комментарии
А как бы вы сами ответили на этот вопрос? И дополнительный вопрос: в каких местах в вашем вопросе выкручены люфты? :)
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оригинал и комментарии
Оставить отзыв с помощью аккаунта FaceBook: